Sequential decision making (SDM), an essential component of autonomous systems, is a characteristic shared across a variety of fields including but not limited to robotics, automatic control, artificial intelligence, economics, and medicine. SDM tasks are typically formalized as reinforcement learning (RL) problems. Reinforcement learning can optimally solve decision and control problems involving complex dynamic systems, without requiring a mathematical model of the system. In RL, agents live in an environment they can percept through sensory inputs and affect by taking actions. The goal is to acquire optimal behaviors by maximizing total-payoff signals which quantify performance of executed actions. RL has been successfully applied to the automatic control of various robotic platforms (e.g., [9]) including the control of helicopter unmanned aerial vehicles [10].
Although significant progress has been made on developing algorithms for learning isolated SDM tasks, these algorithms often require a large amount of experience before achieving acceptable performance. This is particularly true in the case of high dimensional SDM tasks that arise in a variety of real-world scenarios. The cost of this experience can be prohibitively expensive (in terms of both time and fatigue of the robot’s components), especially in scenarios where an agent will face multiple tasks and must be able to quickly acquire control policies for each new task. Another failure mode of conventional methods is that when the production environment differs significantly from the training environment, previously learned controllers may no longer apply.
Learning from scratch, in which agents have to base reasoning on random environmental interactions, is considered to be the major contributor to these aforementioned RL short-comings. Given its psychological roots [7], RL can be compared to human learning. Humans, however, acquire knowledge through what has been theorized as continual transfer learning (i.e., lifelong learning), where new concepts are conceived in relation to others [8]. Lifelong learning is a key characteristic of human intelligence, enabling us to continually build upon and refine our knowledge over a lifetime of experience. This process of continual learning and transfer allows us to rapidly learn new tasks, often with very little training. Over time, this process enables the development of a wide variety of complex abilities across many domains.
The goal of my research is to develop lifelong reinforcement learning methods that continually transfer knowledge between consecutive learning tasks. The approach frames lifelong learning as an online multi-task learning problem with bounded resources (e.g., limiting data, computational time, etc.). These methods enable learning agents that persist in an environment to continually improve performance with additional experience, and rapidly acquire new skills by transferring previously learned knowledge.
Past Research: During my Ph.D. studies, the focus was on developing transfer algorithms be- tween two reinforcement learning tasks. In transfer learning, source knowledge, available from other tasks, agents, or even humans, is configured through an intertask mapping to produce initial target knowledge. This then initializes target controllers for improved performance.
 Of major importance to the success of transfer, is the intertask mapping which enables and categorizes transfer algorithms [5]. In “shallow” transfer, also referred to as same-domain transfer, tasks differ in their transition probabilities (i.e., probabilistic dynamics), and/or reward functions. Consequently, intertask mappings have to shape rewards and/or relate dynamics. In “deep” transfer (cross-domain transfer), on the other hand, tasks vary in all their constituents, including state and action spaces. Here, intertask mappings are essential to enable transfer by connecting optimal policies across state spaces.
Of major importance to the success of transfer, is the intertask mapping which enables and categorizes transfer algorithms [5]. In “shallow” transfer, also referred to as same-domain transfer, tasks differ in their transition probabilities (i.e., probabilistic dynamics), and/or reward functions. Consequently, intertask mappings have to shape rewards and/or relate dynamics. In “deep” transfer (cross-domain transfer), on the other hand, tasks vary in all their constituents, including state and action spaces. Here, intertask mappings are essential to enable transfer by connecting optimal policies across state spaces.
Prior to my Ph.D. work, inter-task mappings for cross-domain transfer have been manually provided [6], whereby designers define such mappings between pairs of similar tasks. Though appeal- ing, manual design of intertask mappings suffers from two major problems. Firstly, hand-crafting intertask mappings is only possible when tasks are similar enough to the human-eye. Unfortunately, this restricts their application to cases when designers have in-depth knowledge of the intrinsic characteristics of the tasks. Secondly, manually designed mappings are not optimal increasing the susceptibility to negative transfer, the phenomenon where transferring diminishes target performance.
Aiming at an autonomous transfer framework, my thesis provided answers the following there essential steps
1. Source Task Selection: The first question that needs to be answered for successful autonomous transfer is how to choose a relevant source for a target task. Here, a similarity measure correlating with transfer performance is essential for selecting source task(s) to a target. We tackled this problem by proposing a data-driven measure based on samples gathered through environmental interactions. Our approach maps source and target samples to transformed spaces where task similarities reside. We learn this transformation in two steps through a novel deep-learner (density estimator). In the first step, the density estimator is trained using source samples, leading to their description in high-abstraction spaces. In the second, target samples are reconstructed using the source-trained deep learner. The reconstruction error then serves as the basis of the similarity measure since it reflects the deviation between the source and target transitions which represent the tasks dynamics.
2. Autonomous Inter-Task Mappings: Having chosen a source task, the second step is to automatically learn an inter-task mapping relating the two tasks. We proposed three different approaches (see e.g., [3], and [4]), two of which are fully automated, to learn intertask map- pings for cross-domain transfer. The common running theme among these approaches is the transformation of source and target samples to unified spaces, where relations are better manifested. Contrary to common belief, these techniques provided a proof-of-concept to the fact that transfer can be successful even between highly dissimilar tasks where manual mappings are hard to design.
3. Effective and Efficient Transfer: Having chosen a source task and learned the mapping between the source and target, the final step for autonomous transfer is to effectively and efficiently use this knowledge for transferring. On this side, we proposed two algorithms (Transfer Fitted Q-iterations (Tr-FQI) and Transfer Least Squares Policy Iteration (Tr-LSPI) [4]), which share the advantages of their standard reinforcement learning counter-parts for efficient learn- ing. With the aid of transferred samples, our approaches improved learning speeds and reduced sample and time complexities for acquiring optimal behaviors.
The work performed during my dissertation paved-the-way for continual lifelong transfer but mostly focused on transferring between two reinforcement learning tasks. Improved performance, however, can be gained from access to samples belonging to multiple tasks. When data is in limited supply, learning task models jointly through multi-task learning (MTL) rather than independently can significantly improve model performance [11]. However, MTL’s performance gain comes at high computational cost when learning new tasks or when updating previously learned models.
Current Research: Being a continuation of my thesis work, my post-doctoral studies focus on extending transfer to benefit from the more realistic multi-task setting, while ensuring reduced computational costs through online learning. It also aims to provide techniques for transferred controllers to meet safety constraints which are essential for real-world applications.
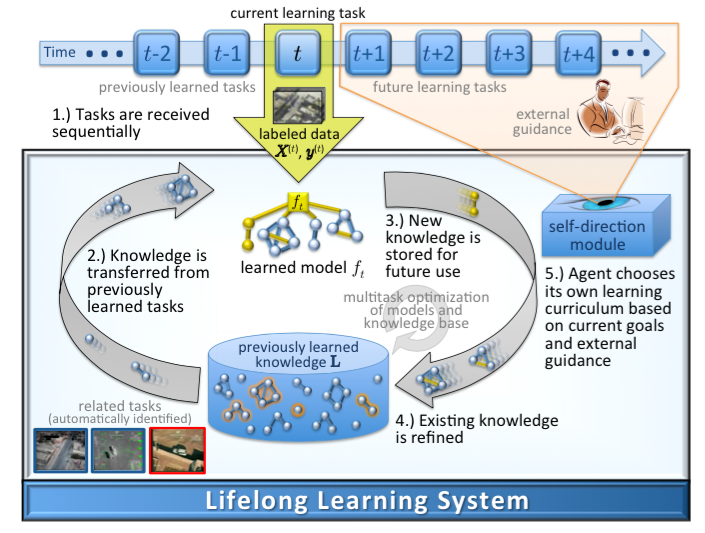 Online Multi-Task Learning for Policy Gradient Methods: Policy gradient methods [9] are reinforcement learning techniques which have shown success in solving high-dimensional problems, such as robotic control. These methods represent the policy (i.e., controller) using a vector of parameters which is fitted upon environmental interactions to maximize total dis- counted payoff. Policy Gradient Efficient Lifelong Learning Algorithm (PG-ELLA) is an online MTL approach designed to learn a sequence of same-domain SDM tasks with low computational overheard [1]. PG-ELLA enables a learner to accumulate knowledge over its lifetime and efficiently share this knowledge between SDM tasks to accelerate learning. Instead of learning a control policy from scratch, as in standard policy gradient methods, our approach rapidly learns a high-performance control policy based on the agent’s previously learned knowledge. Knowledge is shared between SDM tasks via a latent repository that captures reusable components of the learned policies. The latent basis is then updated with newly acquired knowledge, enabling a) accelerated learning of new task models, and b) improvements in the performance of existing models without retraining on their respective tasks. The latter capability is especially important in ensuring that the agent can accumulate knowledge over its lifetime across numerous tasks without exhibiting negative transfer. We show that this process is highly efficient with robust theoretical guarantees. We evaluate PG-ELLA on four dynamical systems, including an application to quadrotor control, and show that PG-ELLA outperforms standard policy gradients both in the initial and final performance.
Online Multi-Task Learning for Policy Gradient Methods: Policy gradient methods [9] are reinforcement learning techniques which have shown success in solving high-dimensional problems, such as robotic control. These methods represent the policy (i.e., controller) using a vector of parameters which is fitted upon environmental interactions to maximize total dis- counted payoff. Policy Gradient Efficient Lifelong Learning Algorithm (PG-ELLA) is an online MTL approach designed to learn a sequence of same-domain SDM tasks with low computational overheard [1]. PG-ELLA enables a learner to accumulate knowledge over its lifetime and efficiently share this knowledge between SDM tasks to accelerate learning. Instead of learning a control policy from scratch, as in standard policy gradient methods, our approach rapidly learns a high-performance control policy based on the agent’s previously learned knowledge. Knowledge is shared between SDM tasks via a latent repository that captures reusable components of the learned policies. The latent basis is then updated with newly acquired knowledge, enabling a) accelerated learning of new task models, and b) improvements in the performance of existing models without retraining on their respective tasks. The latter capability is especially important in ensuring that the agent can accumulate knowledge over its lifetime across numerous tasks without exhibiting negative transfer. We show that this process is highly efficient with robust theoretical guarantees. We evaluate PG-ELLA on four dynamical systems, including an application to quadrotor control, and show that PG-ELLA outperforms standard policy gradients both in the initial and final performance.
Safe Online Multi-Task Learning for Policy Gradient Methods: Although successful, PG-ELLA might produce policy parameters in regions of the policy space which are known to be dangerous. This unfortunate property could be traced back to the standard gradient-based algorithms at PG-ELLA’s core, which solve unconstraint optimization problems. Moreover, the latent repository, sharing knowledge across the same-domain tasks, is also free of constraints. This, however, might generate uninformative latent bases which could potentially lead to the selection of dangerous policies.
A desirable property for real-world applications, therefore, would be a guarantee that policies will remain within predicted safe regions. Our safe online multi-task learner for policy gradients (sPG-ELLA), extends PG-ELLA to the constraint online lifelong learning setting by incorporating restrictions on both the policy spaces and the shared repository ensuring bounded and safe policy parameters. We propose techniques capable of handling such an optimization problem online and show that our approach is highly efficient with robust theoretical guarantees. Precisely, we show that our approach exhibits linear (in the number of tasks) regret over its lifetime. We evaluate sPG-ELLA on a set of dynamical systems and demonstrate its capability of efficiently acquiring safe-policies. We are currently working on applying sPG-ELLA in a set of real-world scenarios including experiments on the PR2 robot available at the Grasp laboratory at the University of Pennsylvania.
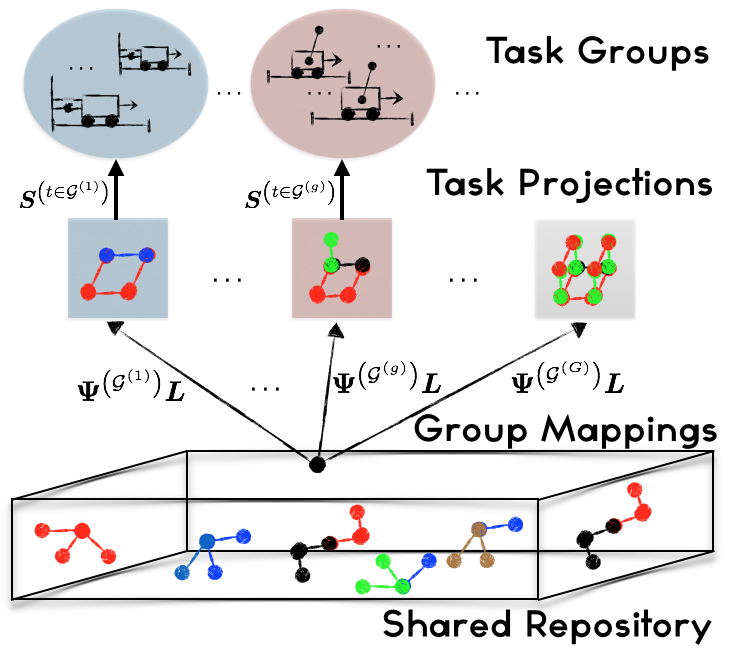 Cross-Domain Online Multi-Task Learning for Policy Gradient Methods: Given all the same-domain lifelong transfer successes, we developed an online cross-domain transfer method for policy gradient reinforcement learning titled PG-Inter-ELLA. PG-Inter-ELLA exhibits three main advantages over existing approaches: a) it improves on traditional transfer learning approaches by explicitly optimizing performance across the source tasks, b) it does not require hand-coded cross-domain mappings in order to transfer knowledge between differing domains, and c) it can share knowledge between a multitude of tasks in a computationally efficient manner. Our approach learns high-performance control policies by autonomously tailoring shared knowledge using group-specific (i.e., domain specific) mappings. These mappings are then rapidly updated after observing new tasks potentially belonging to different domains. Empirical results on controlling difficult tasks, such as, the cart-pole and the three-link cart- pole demonstrated that our approach outperforms others in both the initial and final performance. Theoretical convergence results also show that our algorithm becomes increasingly stable as the number of groups or tasks grow large.
Cross-Domain Online Multi-Task Learning for Policy Gradient Methods: Given all the same-domain lifelong transfer successes, we developed an online cross-domain transfer method for policy gradient reinforcement learning titled PG-Inter-ELLA. PG-Inter-ELLA exhibits three main advantages over existing approaches: a) it improves on traditional transfer learning approaches by explicitly optimizing performance across the source tasks, b) it does not require hand-coded cross-domain mappings in order to transfer knowledge between differing domains, and c) it can share knowledge between a multitude of tasks in a computationally efficient manner. Our approach learns high-performance control policies by autonomously tailoring shared knowledge using group-specific (i.e., domain specific) mappings. These mappings are then rapidly updated after observing new tasks potentially belonging to different domains. Empirical results on controlling difficult tasks, such as, the cart-pole and the three-link cart- pole demonstrated that our approach outperforms others in both the initial and final performance. Theoretical convergence results also show that our algorithm becomes increasingly stable as the number of groups or tasks grow large.
Please note that the previously described approaches are equally applicable to various reinforcement learning algorithms, including temporal-difference learning [2] and sample-based RL methods. Our choice of policy gradients can be traced-back to their successes in controlling high dimensional and complex robotic tasks. Currently, we are working on developing: (1) a safe counter-part to PG- Inter-ELLA allowing its application to real-world scenarios, and (2) a non-parametric lifelong learner for both reinforcement and supervised machine learning. The goal is to truly propose a safe lifelong machine learner which can be applied across a variety of scientific fields.
Apart from transfer and lifelong learning, computational efficiency for improved RL can also be acquired from developing relevant distributed optimization algorithms. On that side, we have proposed a distributed second-order solver for optimization problems with bounded resources. An application, to image segmentation has shown that our distributed algorithm can achieve state-of-the-art segmentation results with O(n) computational complexity. Interestingly, these results are achieved by requiring only R-Hop (i.e., restricted resource) neighborhood information. At this stage, we are modifying our method to suit reinforcement learning problems with the aim of further decreasing computational complexities.
Future Research: As robots become more widely available, the need for control flexibility and ubiquitous general purpose automation is ever-growing. Currently, however, successful robotic control requires substantial expert knowledge in designing task-specific behaviors. If we are to fulfill the promise of general purpose commercial machines suitable for a wide range of user-specified applications, end-user programming is essential. Lifelong transfer learning can serve as one of the promising directions in allowing commercially used robots to continually learn successful behaviors towards achieving an end-user’s demanded task. My future work will primarily focus on extending previously presented techniques to allow for real and safe general purpose machines.
Based on a knowledge repository, robots can possess the capability of automatically adapting current knowledge to solve novel tasks. To clarify, assume the incorporation of task relationships in our lifelong learner, which can be easily achieved by providing relevant priors over policy parameters. Having learned task similarities, novel tasks, imposed by end-users, can be localized in the task relationship graph (derived from the task relationship distribution). To successfully accomplish the new task, the goal now is to build an optimal sequence of tasks expanding the knowledge repository in the novel task’s direction while abiding by safety constraints. Interestingly, this technique resembles similarities to how humans perform continual learning. When faced with a complex task, we typically tend to dissect the task to simpler related assignments, which upon their solution acquired concepts generalize back to the original problem. In future, I aim to further analyze this connection for further proposing robust continual learning algorithms.
On the application side, a field which can benefit from lifelong transfer learning is fault-tolerant con- trol. In fault control, agents are required to handle unanticipated changes in the system’s behavior which occur during the execution phase. These faults can radically alter the dynamics rendering pre- designed controllers inapplicable. Unfortunately, state-of-the-art fault tolerant controllers require substantial amount of learning times and experience for successful control adaptation. The cost of this experience is prohibitively expensive in a field where samples are scarce and increased learning times are catastrophic. Clearly, reusing source fault knowledge will aid in efficiently adapting con- trollers to handle such faulty systems. In future, I plan on proposing new-generation fault-tolerant controllers which benefit from continual lifelong and transfer capabilities for increased controller robustness, performance, and adaptability. Application domains will involve commercial aircraft simulators paving the way for equipping real aircrafts with these newly developed fault controllers. To acquire funding for developing the above algorithms, grant proposal have been and will be submitted. Already, a national science foundation (NSF) proposal has been delivered for further improving the robustness of our lifelong learning methods. The major goal here, is to automate the choice of free parameters (e.g., the size of the latent space, the learning rates, etc.) essential for our algorithms, as well as to quantify their impact on the overall transfer performance. On the fault-tolerance side, I am in the sequel of finalizing two grants to be submitted to the National Robotic Initiative (NRI) and the Air-Force for potential funding resources.
Reference
[1] Haitham Bou Ammar, Eric Eaton, Paul Rovolu, and Matthew E. Taylor Online Multi-Task Learning for Policy Gradient Methods, International Conference on Machine Learning (ICML), 2014.
[2] Vishnu Purushothaman Sreenivasan, Haitham Bou Ammar, and Eric Eaton, Online Multi-Task Gradient Temporal Difference Learning, In Proceedings of the 28th AAAI conference on Artificial Intelligence (Student Abstract).
[3] Haitham Bou Ammar, Decebal Mocanu, Matthew E. Taylor, Karl Tuyls, Kurt Driessens, and Gerhard Weiss, Automatically Mapped Transfer via Three-Way Restricted Boltzmann Machines, European Conference on Machine Learning (ECML), 2013.
[4] Haitham Bou Ammar, Matthew E. Taylor, Karl Tuyls, Kurt Driessens, and Gerhard Weiss , Reinforcement Learning Transfer Using Sparse Coding, International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS), 2012.
[5] Haitham Bou Ammar, Siqi Chen, Karl Tuyls, and Gerhard Weiss, Reinforcement Learning Trans- fer a Survey and Formal Framework, In the German Journal of Artificial Intelligence (KI), Springer 2013.
[6] Matthew E. Taylor and Peter Stone, Transfer Learning for Reinforcement Learning Tasks: A Survey, The Journal of Machine Learning Research 10, 1633-1685.
[7] Richard S. Sutton and Andrew G. Barto, Reinforcement Learning: An Introduction, MIT Press, Cambridge, MA, 1998.
[8] Perkins D. and Saloman G., Transfer of Learning, In T. Husen and T. Postlethwaite (eds), The International Encyclopaedia of Education 2nd Edition, Oxford: Elsevier Science Ltd.
[9] J. Kober, and J. Peters, Policy Search for Motor Primitives in Robotics, In Machine Learning, 84(1-2), July 2011.
[10] Andrew Ng, Adam Coates, Mark Diel, Varun Ganapathi, Jamie Schulte, Ben Tse, Eric Berger, and Eric Liang, Autonomous Inverted Helicopter Flight via Reinforcement Learning, In Interna- tional Symposium on Experimental Robotics, 2004.
[11] Thrun S., and O’Sullivian J, Discovering structure in multiple learning tasks: the TC algorithm, In Proceedings of the 13th International Conference of Machine Learning (ICML), 1996.